



数据结构与算法概论
数据结构是计算机科学的基石之一,它是计算机程序在内存中存储和组织数据的方式。
早期的计算机主要应用于科学计算,随着计算机的发展和应用范围的拓宽,计算机需要 处理的数据量越来越大,数据的类型越来越多,数据的结构越来越复杂,计算机的对象从简 单的纯数值性数据发展为非数值性的和具有一定结构的数据。
就像是一个巨大的文档资料室或者图书馆,刚开始只有较少的资料,我们随意摆放,当我们需要寻找一本书时,我们也可以很快的找到它。
但是如果书籍开始增多,对于几十本书或者百多本书,我们要想快速查找某一本,那么我们就需要开始将他们分类,并且按照字典序列排列整齐,如果有更多的书,几千上万本,那么我们可能需要给书架编号分类并记录对应的信息(索引),这样当我在成千上万的书籍中寻找一本《计算机数据结构》就只需要先拿到书单目录,找到计算机分类对应的书架编号,然后顺序寻找对应的书架后,然后找到更小的类目(如果有的话),最后更具字典顺序寻找“计”开头的区域,在在此区域寻找第二个字为“算”开头的区域,以此类推。
为了应对计算机对于大量数据的索引与处理复杂度问题,计算机科学家们开始研究数据的特性、数据之间存在的关系,以及如何有效地组 织、管理存储数据,从而提高计算机处理数据的效率。
数据结构的概念最早由c.A.R.Hoare和N.Wirth在1966年提出,对这一发展做出杰出贡献的是D.E.Kunth和C.A.R Hoare,D. E. Kunth的《计算机程序设计技巧》和C.A.R.Hoare的《数据结构札记》,这两部著作对数据结构这门学科的发展做出了重要贡献。
20世纪60年代初期,“数据结构“ 有关的内容散见于操作系统、编译原理等课程中。1968 年,“数据结构” 作为一门独立的课程 被列入美国一些大学计算机科学系的教学计划,同年,著名 计算机科学家D.E.Knuth 教授发表了《计算机程序设计艺术》 第一卷《基本算法》。
大量关于程序设计理论的研究表明:对大型复杂程序的构造进行系统而科学的研究,必须对这些程序中所包含的数据结构进行深入的研究。
随着计算机科学的飞速发展,到20世纪80年代初期,数据结构的基础研究日渐成熟,已经成为一门完整的学科。
随着大型程序和大规模文件系统的出现,结构化程序设计成为程序设计方法学的主要研究方向,人们普遍认为程序设计的实质就是对所处理的问题选择一种好的数据结构,并在此结构基础上施加一种好的算法。
算法(英语:algorithm),在()和之中,指一个被定义好的、计算机可施行其指示的有限步骤或次序[,常用于、和。算法可以使用条件语句通过各种途径转移代码执行(称为自动决策),并推导出有效的推论(称为自动推理),最终实现自动化。
相反,是一种解决问题的方法,可能没有完全指定,也可能不能保证正确或最优的结果,尤其是在没有明确定义的正确或最优结果的问题领域。[例如,社交媒体依赖于启发式,尽管在21世纪的流行媒体中被广泛称为算法,但由于问题的性质,它无法提供正确的结果。
早在尝试解决提出的时,算法的不完整概念已经初步定型;在其后的正式化阶段中人们尝试去定义“[”或者“[”。这些尝试包括、和分别于1930年、1934年和1935年提出的,于1936年提出的,1936年的和1937年提出的。即使在当下,依然常有符合直觉的想法难以定义为形式化算法的情况。[
算法是,包含一系列定义清晰的指令[,并可于时间及空间内清楚的表述出来[。算法中的指令描述的是一个,它时从一个初始状态和初始输入(可能为)开始,[经过一系列有限[而清晰定义的状态最终产生输出[并停止于一个终态。 一个状态到另一个状态的转移不一定是。 包括在内的一些算法,都包含了一些随机输入。
对于算法的概念,具体可查阅维基百科。
数据结构基本概念
数据
数据是信息的载体,是描述客观事物属性的数字、字符以及所有能输入到计算机中并被计算机程序识别和处理的符号的集合。
数据时计算机程序加工的原料。
数据元素
数据元素是数据的基本单位,通常作为一个整体进行考虑和处理。
一个数据元素由若干数据项组成,数据项是构成数据元素的不可分割的最小单位。
数据对象
数据对象是具有相同性质的数据元素的集合。
数据类型
数据类型是一个值的集合和定义在此集合上的一组操作的总称。
数据类型分为以下四种:
-
原子类型:其值不可再分的数据类型。
-
结构类型:其值可以分成若干成分或者分量的数据类型。
-
抽象数据类型:一个数学模型以及定义在该数学模型上的一组操作。
数据结构
数据结构是相互之间存在一种或多种特定关系的数据元素集合。
在任何问题中,数据元素不是孤立存在的,它们之间存在某种关系,这种数据元素之间的关系称为结构。
数据结构包含以下三方面内容;
-
逻辑结构。
-
存储结构。
-
数据运算。
数据的逻辑结构与存储结构是密不可分的两个方面,一个算法设计取决于所选定的逻辑结构,而算法的实现依赖于采用的存储结构。
-
数据:就像是你家里的书架上摆放的各种书籍一样,它们是我们想要处理和存储的信息。
-
数据元素:每一本书就像是书架上的一本书,它们是数据的基本单元,比如《哈利·波特与魔法石》或者《计算机科学导论》。
-
数据对象:所有的书籍集合就像是整个书架,它们一起构成了一个数据对象。
-
数据类型:
-
原子类型:就像书籍的具体信息,比如书名、作者、页数等,它们是不可再分的最基本的数据类型。
-
结构类型:就像书籍的不同部分,比如章节、段落、页码等,它们可以分成若干成分或者分量,每个成分可能是原子类型或者结构类型。
-
抽象数据类型:就像书架的功能一样,它是一种抽象的概念,定义了一组操作和数据的集合。用户只需要知道如何使用这些操作来访问和操作数据,而不需要了解内部的具体实现细节。
-
-
数据结构:就像书架上书籍的排列方式,比如按照作者、书名的首字母或者主题分类。这种排列方式构成了书架的数据结构,使得我们可以更轻松地找到需要的书籍。
数据结构三要素
数据的逻辑结构
数据结构是指数据元素之间的逻辑关系,也就是说,从逻辑关系上描述数据。
数据结构与数据的存储无关,是独立于计算机的。
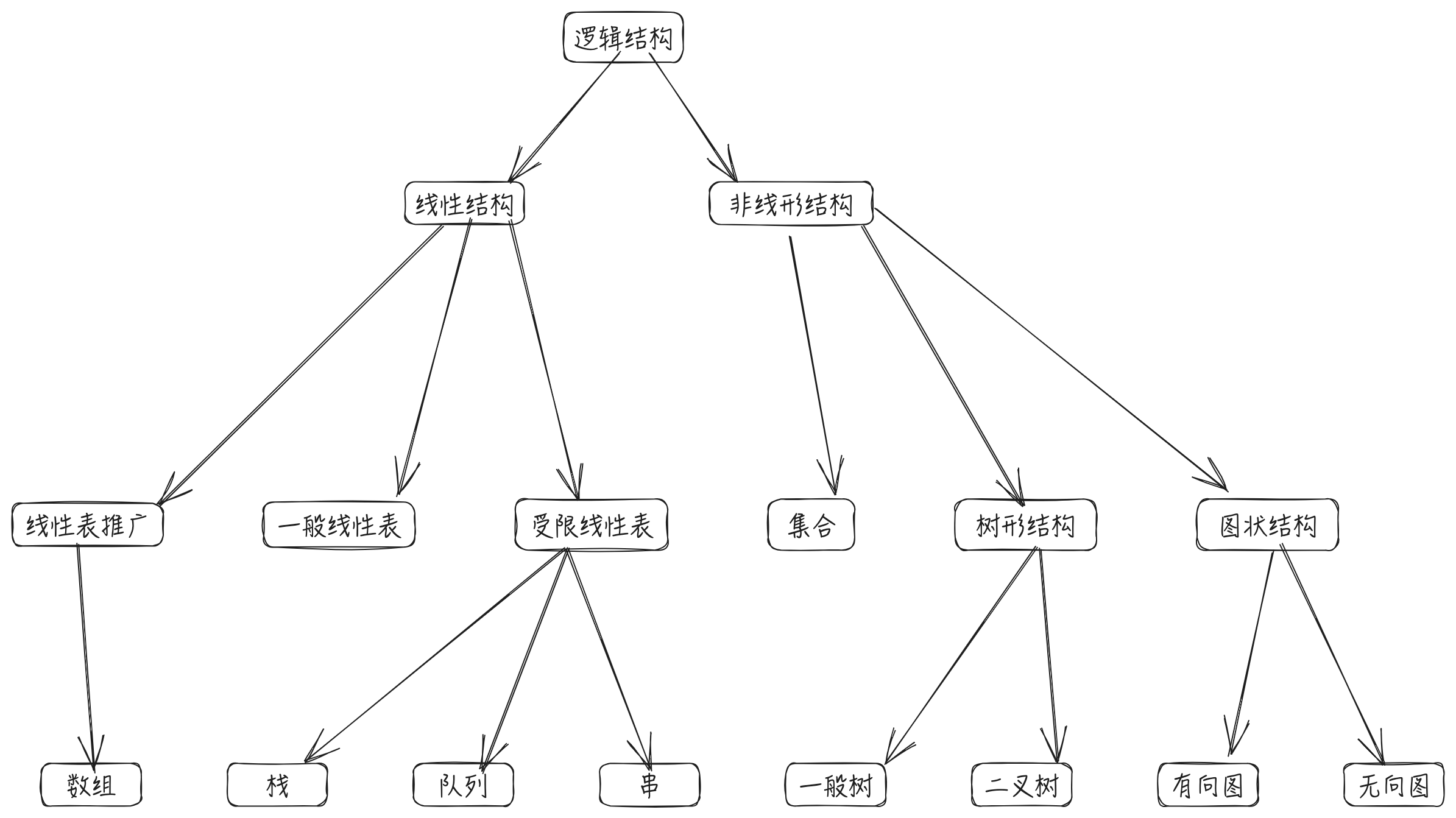
数据的逻辑结构分为线性结构与非线性结构。
线性表就是典型的线性结构,集合、树和图这些是典型的非线性结构。
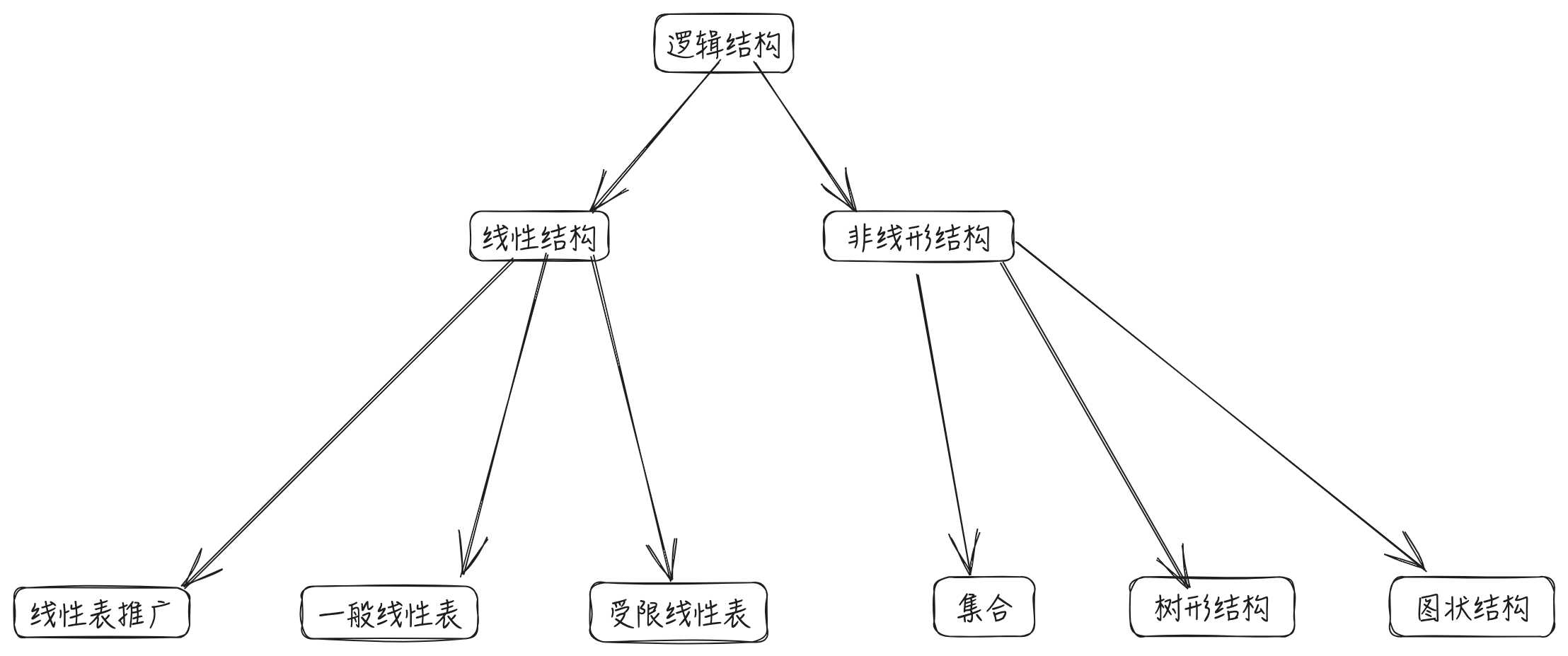
对其子类再继续向下还可以划分出更多种类,这里就不展示了。
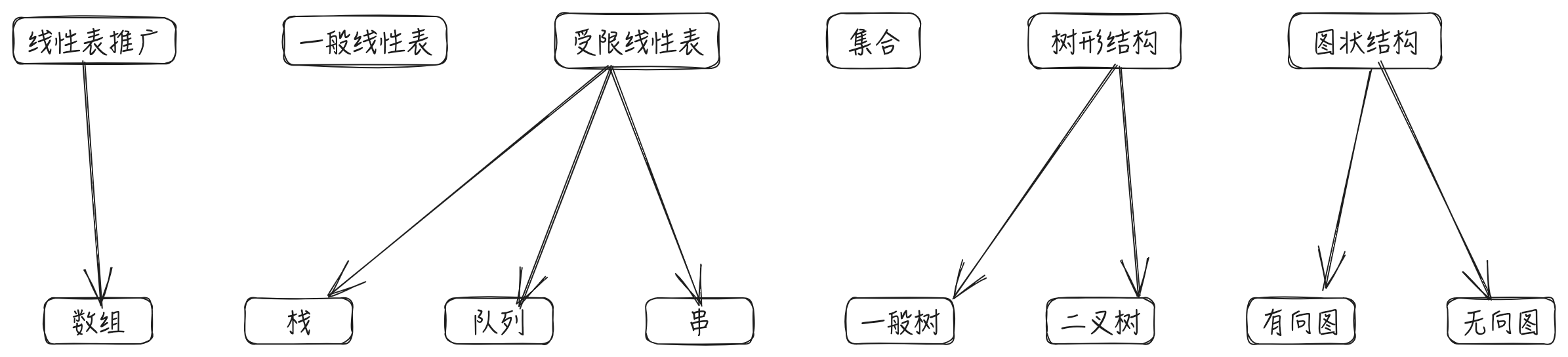
完整的结构分类图如下:
-
集合:结构中的数据之间除了“同属于一个集合”外,没有其他关系。
-
线性结构:结构中的数据元素之间只存在一对一的关系。
-
树形结构:结构中的数据元素之间存在一对多的关系。
-
图状结构/网状结构:结构中数据元素之间存在多对多的关系。
如果不太好理解,建议搜索对应数据结构的可视化形状,这样看起来更加形象。
我推荐阅读Hello Algo这个网站:https://www.hello-algo.com。
数据的存储结构
存储结构是指数据结构在计算机中的表示(也叫做映像),也称为物理结构。
存储结构包括数据元素的表示和关系的表示。
数据的存储结构是用计算机语言实现的逻辑结构,它依赖于计算机语言。
数据的存储结构主要有以下几种:
-
顺序存储:
-
逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关系由存储单元的邻接关系来体现。
-
可以实现随机存取,每个元素占用最少的存储空间。
-
只能使用相邻的一整块存储单元,可能产生较多的外部碎片。
-
-
链式存储:
-
不要求逻辑上相邻的元素在物理位置上也相邻,借助指示元素存储地址的指针来表示元素之间的逻辑关系。
-
不会出现碎片现象,能够充分利用所有存储单元。
-
每个元素的指针也需要占用一部分空间,并且只能顺序存取。
-
-
索引存储:
-
在存储元素的信息的同时,还建立附加的索引表。
-
索引表中的每项称为索引项,索引的一般形式是:<关键词,地址>。
-
检索速度快。
-
附加的索引表需要额外占用一定的存储空间,并且增加和删除数据时,也需要修改索引表,所以需要花费更多时间。
-
-
散列存储:
-
根据元素的关键字直接计算出改元素的存储地址,又称哈希存储。
-
检索、增加和删除节点的操作非常快。
-
依赖于散列函数,不好的散列函数可能导致元素存储单元冲突,也就是我们常说的哈希冲突,解决冲突会增加时间和空间的开销。
-
数据运算
施加在数据上的运算包括运算的定义和实现。
数据运算的定义是针对逻辑结构的,指出运算的功能。
数据运算的实现是针对存储结构的,指出运算的具体操作步骤。
算法的基本概念
算法是指对特定问题求解步骤的一种描述,它是指令的有限序列,其中每一条指令表示一个或者多个操作。
算法具有下列五个重要特性:
-
有穷性:一个算法必须总在执行有穷步之后结束,且每一步都可在有穷时间内完成,说人话就是一定要能结束。
-
确定性:算法中的每一条指令必须有确切的含义,对于相同的输入只能得到相同的输出。
-
可行性:算法中描述的操作都可以通过已经实现的基本运算执行有限次来实现。
-
输入:一个算法有零个活着多个输入,这些输入取自某个特定的对象的集合。
-
输出:一个算法至少存在一个输出,输出与输入有着某种特定关系的量。
设计一个优质的算法需要尽可能实现以下目标:
-
正确性:正确求解。
-
可读性:算法应该具有良好的可读性。
-
健壮性:能够对非法数据做出反馈,而不会产生莫名其妙的输出。
-
高效率:效率是指算法的执行时间效率。
-
低存储量需求:存储量需求是指算法执行过程中所需要的最大存储空间。
算法的效率度量
我们通常使用时间复杂度与空间复杂度来度量算法的效率。
时间复杂度
一个语句的频度是指该语句在算法中被重复执行的次数。
算法中所有语句的频度之和计作T(n),它是该算法问题规模n的函数,时间复杂度主要是分析T(n)的数量级。
算法中基本运算(最深层次循环中的语句)的频度与T(n)同数量级,因此通常将算法中的基本运算的执行次数的数量级作为该算法的时间复杂度。
时间复杂度记为:T(n) = O(f(n))。
O的含义是T(n)的数量级。
这里不做复杂阐述,需要更详细的了解可以查阅维基百科:https://zh.wikipedia.org/wiki/%E6%97%B6%E9%97%B4%E5%A4%8D%E6%9D%82%E5%BA%A6。
一般总是考虑在最坏的情况下的时间复杂度,以保证算法的运行时间不会比它更长。
算法的时间复杂度是衡量算法执行时间随输入规模增长而变化的度量,通俗来说,它描述了算法执行所需时间与输入规模之间的关系,以指导我们选择合适的算法来解决问题。
举例来说,假设有一个排序算法,对于输入大小为n的列表,如果该算法的执行时间与n的平方成正比,我们就说这个算法的时间复杂度是O(n^2),表示执行时间随着输入规模的增加而呈平方增长。
常见的时间复杂度包括:
-
O(1):常数时间复杂度,算法的执行时间与输入规模无关,如访问数组中的一个元素。
-
O(log n):对数时间复杂度,如二分查找算法。
-
O(n):线性时间复杂度,算法的执行时间与输入规模成正比,如线性搜索算法。
-
O(n log n):如快速排序、归并排序等。
-
O(n^2):平方时间复杂度,如简单的嵌套循环算法。
-
O(2^n):指数时间复杂度,如穷举搜索算法。
按照最优来排列这些时间复杂度,通常是从O(1)到O(log n),然后是O(n),O(n log n),O(n2),最后是O(2n)。因为O(1)是最优的,表示算法执行时间与输入规模无关;而O(2^n)则是最差的,表示算法执行时间随着输入规模呈指数增长,效率较低。
想象一下你要给一摞纸张编号,每一张都是一张参考卡片。如果你只有一张纸,那就只需要一秒钟,无论编号多少。这就是 O(1) 的时间复杂度,因为无论纸张有多少,你只需要一个动作就能完成。
但是,如果你有很多纸张,比如100张,那你要一张一张地编号,这就是 O(n) 的时间复杂度,因为编号所需的时间与纸张的数量成正比。
如果你的编号方法是每次翻倍地批量编号,比如先处理2张,然后4张,然后8张……这就是 O(log n) 的时间复杂度。这样的方式会比 O(n) 的方式快得多。
最后,如果你的编号方法是每张纸都和每张纸对比,确保每张纸都在正确的位置上,那就是 O(n^2) 的时间复杂度。这种方法会非常耗时,特别是当纸张数量增加时,时间会快速增长。
所以,时间复杂度就是告诉我们随着问题规模增加,算法执行所需时间的增长速度。
我们希望尽可能地选择时间复杂度低的算法来解决问题,这样能够更快地得到结果。
空间复杂度
算法的空间复杂度S(n)定义为该算法所需的存储空间,它是问题规模n的函数。
空间复杂度记为:S(n) = O(g(n))。
若输入数据所占空间只取决于问题本身,和算法无关,则只需要分析输入和程序之外的额外空间。
这句话的意思是,有时候我们解决一个问题时,输入数据所占用的空间是固定的,不随着我们选择不同的算法而改变。
举个例子,假设我们要对一组数字进行排序。无论我们使用哪种排序算法(比如冒泡排序、快速排序等),这组数字本身的存储空间是固定的,它只取决于问题本身,与我们选择的算法无关。
所以在分析算法的空间复杂度时,我们主要关注的是算法执行过程中额外使用的内存空间,而不是问题本身所占用的空间。
因此,这句话强调了在分析空间复杂度时要关注算法对额外内存空间的使用情况。
算法的空间复杂度是指在算法执行过程中所需要的额外内存空间,这包括算法执行时使用的内存,比如临时变量、数据结构、缓存等,但不包括输入数据所占用的空间,通俗地说,空间复杂度描述了算法对内存资源的需求程度。
假设你在做菜时需要一个额外的桌子来准备食材和工具,这个桌子的大小取决于你要做的菜的复杂程度。
如果是做简单的凉拌黄瓜,你可能只需要一个小桌子就够了,无论你准备多少份,这就像是 O(1) 的空间复杂度,因为你只需要一个固定大小的桌子来完成任务,无论菜的数量有多少。
但如果你要做一道需要很多炉灶、切菜板和炊具的复杂菜肴,你可能需要更大的空间来摆放这些工具和食材,这就像是 O(n) 的空间复杂度,因为你需要的桌子大小会随着菜肴的复杂程度和份量的增加而增加。
常见的空间复杂度包括:
-
O(1):常数空间复杂度,无论输入规模大小如何,算法所需的额外内存空间都是固定的,就像上面提到的小桌子。
-
O(log n):对数空间复杂度,随着输入规模的增加,算法所需的额外内存空间以对数方式增长,就像是你做的菜越复杂,需要的空间增长速度变慢一样。
-
O(n):线性空间复杂度,额外内存空间随着输入规模的增加而线性增长,就像需要更大的桌子来容纳更多的食材和工具。
-
O(n log n):某些算法的空间复杂度,比如某些分治算法,空间占用随着输入规模的增加而增长,但增长速度比线性慢,就像是准备复杂菜肴时,需要的桌子大小不是线性增长的。
-
O(n^2):平方空间复杂度,额外内存空间随着输入规模的增加呈平方增长,就像是需要一个大桌子来摆放很多很多的食材和工具。
